Pytorch 自定义网络类的参数
真的是要被自己蠢哭了
事情是这样的,最近在用deep learning的方法解pde,然后代码写到了保存和读取网络参数的部分,发现载入参数后的网络会生成和训练时不一样的结果;更令人奇怪的是这个结果每次运行都不一样。
比如说训练完保存前网络输出长这样:
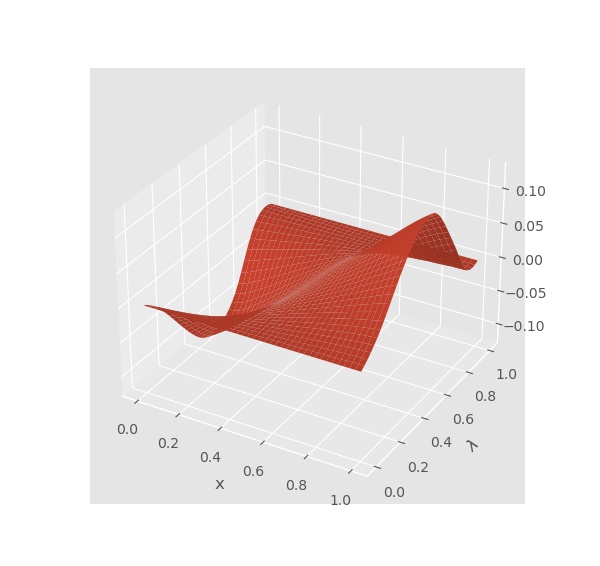 通过读取保存的参数文件重建后的输出长这样:
通过读取保存的参数文件重建后的输出长这样:
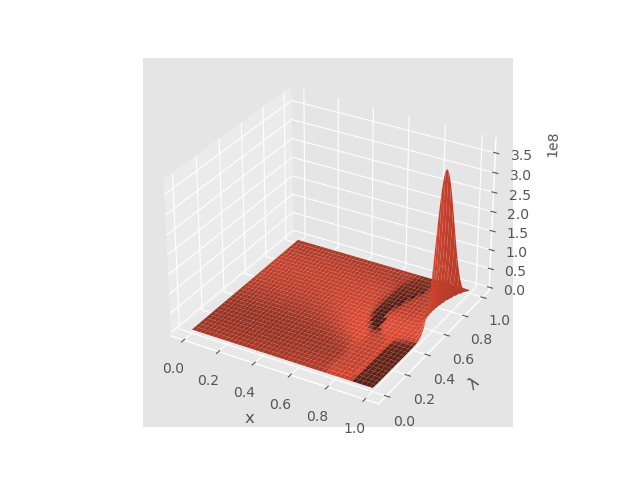 呃……我寻思好像也没有dropoff和其他随机的layer啊,而且也设置了
呃……我寻思好像也没有dropoff和其他随机的layer啊,而且也设置了model.eval()。上网搜了一些论坛后觉得可能是参数保存的问题……?
先来看一下我自己写的resnet实现:
class ResNet(nn.Module):
def __init__(self, d, m, activation="elu", groups=2):
super(ResNet, self).__init__()
self.d = d
self.m = m
self.preprocess = nn.Linear(d, m)
self.groups = groups
self.block_per_group = 2
self.res_fcs = [[nn.Linear(m, m) for _ in range(self.block_per_group)] for _ in range(self.groups)]
self.fc = nn.Linear(m, 1)
if activation == "relu":
self.activation = lambda x: Func.relu(x)
#...
def forward(self, x):
z = self.preprocess(x)
for group in self.res_fcs:
z_id = z
for block in group:
z = self.activation(block(z))
z = z_id + z
return self.fc(z)
是不是感觉特别优雅?写完还觉得这样就不用手写跳接层,多方便呀。结果看了一眼model.state_dict():
>>> model.state_dict()
OrderedDict([('preprocess.weight', tensor(...)), ('preprocess.bias', tensor(...)), ('fc.weight', tensor(...)), ('fc.bias', tensor(...))])
我去……整个人都傻了……也就是说只有preprocess和fc这两个layer是别识别成可训练/可保存的,其它的都被无视了。
想想好像也有道理……毕竟res_fcs是一个list,长的不像layer。解决办法感觉是用ModuleList(文档)(不用自己造轮子了开心)。修改后的代码如下:
self.res_fcs = nn.ModuleList([nn.ModuleList([nn.Linear(m, m) for _ in range(self.block_per_group)]) for _ in range(self.groups)])